Блок 1 — Python Basic (1–6)
- Лекция 1. Введение. Типизации. Переменные. Строки и числа. Булева алгебра. Ветвление
- Лекция 2. Обработка исключений. Списки, строки детальнее, срезы, циклы.
- Лекция 3. None. Range, list comprehension, sum, max, min, len, sorted, all, any. Работа с файлами
- Лекция 4. Хеш-таблицы. Set, frozenset. Dict. Tuple. Немного об импортах. Namedtuple, OrderedDict
- Лекция 5. Функции, типизация, lambda. Map, zip, filter.
- Лекция 6. Алгоритмы и структуры данных
Блок 2 — Git (7–8)
Блок 3 — Python Advanced (9–14)
- Лекция 9. Введение в ООП. Основные парадигмы ООП. Классы и объекты. Множественное наследование.
- Лекция 10. Magic methods. Итераторы и генераторы.
- Лекция 11. Imports. Standard library. PEP 8
- Лекция 12. Декораторы. Декораторы с параметрами. Декораторы классов (staticmethod, classmethod, property)
- Лекция 13. Тестирование
- Лекция 14. Проектирование. Паттерны. SOLID.
Блок 4 — SQL (15–17)
Блок 5 — Django (19–26)
- Лекция 19. Знакомство с Django
- Лекция 20. Templates. Static
- Лекция 21. Модели. Связи. Meta. Abstract, proxy
- Лекция 22. Django ORM
- Лекция 23. Forms, ModelForms. User, Authentication
- Лекция 24. ClassBaseView
- ▶ Лекция 25. NoSQL. Куки, сессии, кеш
- Лекция 26. Логирование. Middleware. Signals. Background Tasks. Messages. Manage commands
Блок 6 — Django Rest Framework (27–30)
Блок 7 — Python async (31–33)
Блок 8 — Deployment (34–35)

NoSQL (от англ. Not Only SQL — «не только SQL») — это термин, обозначающий типы баз данных, отличные от традиционных реляционных СУБД. NoSQL БД предлагают более гибкие модели хранения данных и лучше подходят для масштабируемых распределённых систем.
Важно понимать: NoSQL — это не «замена SQL», а дополнение. В современных проектах часто используются обе технологии вместе, каждая для своих задач.
Подробнее:
| Год | Событие |
|---|---|
| 1970 | Эдгар Кодд публикует реляционную модель данных |
| 1995-2000 | Бум интернета, рост нагрузок |
| 2004 | Google публикует статью о BigTable |
| 2007 | Amazon публикует статью о Dynamo |
| 2009 | Термин «NoSQL» становится популярным |
| 2009 | MongoDB, Redis, Cassandra выходят в open source |
| 2010+ | NoSQL становится мейнстримом |
Реляционные базы данных (PostgreSQL, MySQL) отлично работают, но имеют ограничения:
┌─────────────┐
│ Клиенты │
│ (миллионы) │
└──────┬──────┘
│
▼
┌──────────────┐
│ Один сервер │ ← Узкое место!
│ PostgreSQL │
└──────────────┘
Вертикальное масштабирование (Scale Up):
- Добавляем RAM, CPU, SSD
- Дорого, есть физический предел
- Единая точка отказа
Горизонтальное масштабирование (Scale Out):
- Добавляем больше серверов
- SQL плохо масштабируется горизонтально из-за JOIN и транзакций
| Проблема | Пример |
|---|---|
| Жёсткая схема | Добавление поля требует ALTER TABLE на миллионах строк |
| JOIN на больших данных | Соединение 10 таблиц по 100 млн строк каждая |
| Транзакции между серверами | Распределённые транзакции очень медленные |
| Неструктурированные данные | Логи, события, JSON с разной структурой |
CAP-теорема (также называемая теоремой Брюера) гласит, что в распределённой системе невозможно одновременно обеспечить:
| Свойство | Описание |
|---|---|
| Consistency (Согласованность) | Все узлы видят одинаковые данные в один и тот же момент. |
| Availability (Доступность) | Система всегда отвечает на запрос (даже если это не последняя версия). |
| Partition Tolerance (Устойчивость к разделению) | Система продолжает работать, даже если между узлами есть сетевые проблемы. |
🧠 Зачем нужна CAP-теорема? При проектировании распределённых систем (особенно в NoSQL) часто приходится жертвовать чем-то ради надёжности и масштабируемости. Например:
- В случае сетевого разделения можно либо отказать в доступе (жертвуем A),
- Либо отдать устаревшие данные (жертвуем C).
Вывод: система может выбрать максимум два из трёх свойств одновременно.
Примеры:
- 🔸 Cassandra — AP: предпочитает доступность и устойчивость, согласованность достигается позже (eventual consistency).
- 🔸 MongoDB (до 4.0) — CP: жертвует доступностью при проблемах с сетью.
- 🔸 Redis (в кластере) — чаще AP.
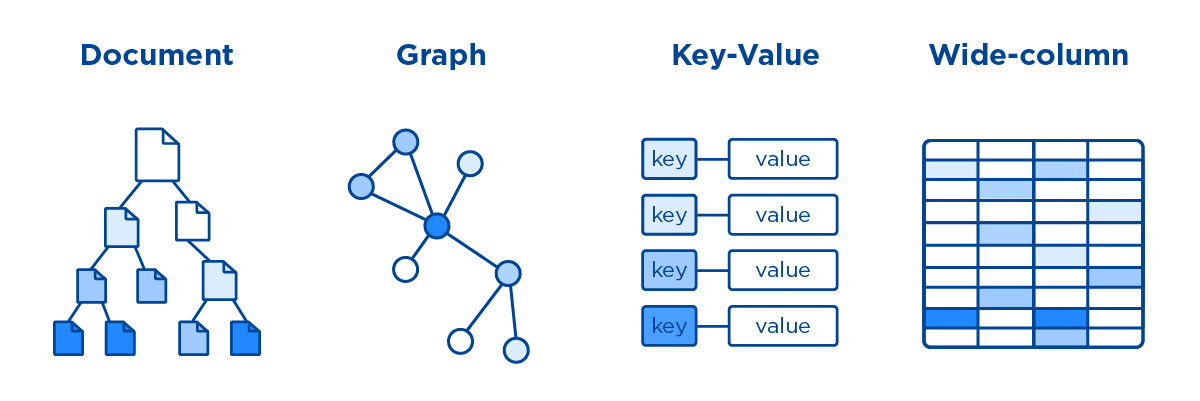
Существует 4 основных типа NoSQL баз данных, каждый оптимизирован под свои сценарии:
Простейшая модель, напоминающая словарь Python: ключ → значение.
┌─────────────────┬──────────────────────────────┐
│ Ключ │ Значение │
├─────────────────┼──────────────────────────────┤
│ user:123 │ {"name": "Alice", "age": 25} │
│ session:abc123 │ {"user_id": 123, "cart": []} │
│ cache:homepage │ "<html>...</html>" │
│ counter:visits │ 1542367 │
└─────────────────┴──────────────────────────────┘
Характеристики:
- ⚡ Очень быстрый доступ O(1)
- 🔑 Поиск только по ключу (нет запросов по значению)
- 📦 Значение — «чёрный ящик» (строка, JSON, бинарные данные)
Популярные решения:
| БД | Особенности | Когда использовать |
|---|---|---|
| Redis | In-memory, структуры данных, Pub/Sub | Кеш, сессии, очереди, real-time |
| Memcached | Только кеш, очень простой | Простое кеширование |
| Amazon DynamoDB | Managed, масштабируемый | AWS-проекты, serverless |
| etcd | Распределённый, консистентный | Конфигурации, service discovery |
Реальные примеры использования:
- GitHub — Redis для очередей задач и кеша
- Twitter — Redis для timeline и счётчиков
- Pinterest — Redis для рекомендаций
Пример паттерна именования ключей:
# Хорошие ключи — структурированные, понятные
"user:123:profile" # профиль пользователя 123
"user:123:sessions" # сессии пользователя
"article:456:views" # счётчик просмотров статьи
"cache:homepage:v2" # кеш главной страницы, версия 2
"ratelimit:ip:192.168.1.1" # rate limiting по IP
# Плохие ключи
"u123" # непонятно что это
"data" # слишком общее
"temp_value_for_user" # нет структурыХранят данные в виде документов (JSON, BSON). Каждый документ — самодостаточная единица с произвольной структурой.
Сравнение с SQL:
SQL (PostgreSQL): Document (MongoDB):
┌─────────────────────────┐ ┌─────────────────────────────────┐
│ users │ │ { │
├────┬───────┬────────────┤ │ "_id": "user_001", │
│ id │ name │ email │ │ "name": "Alice", │
├────┼───────┼────────────┤ │ "email": "alice@example.com", │
│ 1 │ Alice │ alice@... │ │ "orders": [ │
└────┴───────┴────────────┘ │ {"item": "Book", "qty": 2}, │
┌─────────────────────────┐ │ {"item": "Pen", "qty": 5} │
│ orders │ │ ], │
├────┬─────────┬──────────┤ │ "address": { │
│ id │ user_id │ item │ │ "city": "Moscow", │
├────┼─────────┼──────────┤ │ "zip": "123456" │
│ 1 │ 1 │ Book │ │ } │
│ 2 │ 1 │ Pen │ │ } │
└────┴─────────┴──────────┘ └─────────────────────────────────┘
↑ Нужен JOIN! ↑ Всё в одном документе!
Характеристики:
- 📝 Гибкая схема — разные документы могут иметь разные поля
- 🔍 Богатые запросы — можно искать по любому полю
- 📦 Вложенные структуры — массивы, объекты внутри документов
- 🚀 Нет JOIN — данные денормализованы
Популярные решения:
| БД | Особенности | Когда использовать |
|---|---|---|
| MongoDB | Самая популярная, богатый функционал | Общего назначения, прототипы |
| CouchDB | HTTP API, offline-first | Мобильные приложения, синхронизация |
| Firestore | Real-time, managed | Firebase-проекты, мобильные |
| Amazon DocumentDB | MongoDB-совместимый | AWS-проекты |
Когда документная БД лучше SQL:
| Сценарий | Почему документная БД лучше |
|---|---|
| CMS, блоги | Статьи имеют разную структуру (видео, галерея, текст) |
| Каталог товаров | У телефона и футболки разные атрибуты |
| Логи, события | Структура может меняться |
| Прототипирование | Не нужно думать о схеме заранее |
Когда SQL лучше:
| Сценарий | Почему SQL лучше |
|---|---|
| Финансы, банкинг | Нужны ACID-транзакции |
| Сложные отчёты | Нужны JOIN и агрегации |
| Связанные данные | Много связей many-to-many |
Колонночные базы данных на первый взгляд похожи на реляционные, но различие — в физической организации хранения данных.
Row-oriented (PostgreSQL): Column-oriented (Cassandra):
┌────┬───────┬─────┬────────┐ ┌─────────────────────────────┐
│ id │ name │ age │ city │ │ id: [1, 2, 3, 4, 5...] │
├────┼───────┼─────┼────────┤ │ name: [Alice, Bob, ...] │
│ 1 │ Alice │ 30 │ Moscow │ │ age: [30, 25, 28, ...] │
│ 2 │ Bob │ 25 │ Prague │ │ city: [Moscow, Prague, ...]│
│ 3 │ Carol │ 28 │ Berlin │ └─────────────────────────────┘
└────┴───────┴─────┴────────┘
↑ Строки хранятся вместе ↑ Столбцы хранятся вместе
| Реляционные БД (PostgreSQL, MySQL) | Колонночные БД (Cassandra, Bigtable) | |
|---|---|---|
| Единица хранения | строка (row) | столбец (column) или «семейство столбцов» |
| Физическое хранение | строки лежат вместе | значения одного столбца лежат вместе |
| Сценарий оптимизации | запись/чтение строк | аналитика, агрегации по столбцам |
| Гибкость схемы | строго задана | допускаются разные наборы столбцов |
Почему это важно?
-- Этот запрос БЫСТРЕЕ в колонночной БД:
SELECT AVG(age) FROM users WHERE city = 'Moscow';
-- Читаем только 2 столбца (age, city), а не все данные
-- Этот запрос БЫСТРЕЕ в row-oriented БД:
SELECT * FROM users WHERE id = 123;
-- Читаем одну строку целикомПопулярные решения:
| БД | Особенности | Когда использовать |
|---|---|---|
| Apache Cassandra | Распределённая, высокая доступность | Логи, IoT, временные ряды |
| Google Bigtable | Managed, петабайты данных | Big Data, ML |
| ClickHouse | Аналитика, очень быстрый | OLAP, дашборды |
| Apache HBase | На базе Hadoop | Big Data экосистема |
Реальные примеры:
- Netflix — Cassandra для 10+ петабайт данных о просмотрах
- Discord — Cassandra для миллиардов сообщений
- Uber — Cassandra для геолокации и логов
Графовые базы данных хранят данные как узлы (nodes) и связи (edges) между ними.
┌─────────┐
│ Alice │
└────┬────┘
│ FRIEND
▼
┌─────────┐ ┌─────────┐
│ Bob │─WORKS_AT─▶│ Google │
└────┬────┘ └─────────┘
│ LIKES
▼
┌─────────┐
│ Python │
└─────────┘
Язык запросов Cypher (Neo4j):
// Найти друзей друзей Alice
MATCH (alice:Person {name: 'Alice'})-[:FRIEND]->()-[:FRIEND]->(fof)
RETURN fof.name
// Найти кратчайший путь между двумя людьми
MATCH path = shortestPath(
(a:Person {name: 'Alice'})-[:FRIEND*]-(b:Person {name: 'Charlie'})
)
RETURN path
// Рекомендации: "Люди, которые лайкнули то же, что и вы"
MATCH (me:Person {name: 'Alice'})-[:LIKES]->(thing)<-[:LIKES]-(other)
WHERE me <> other
RETURN other.name, COUNT(thing) as common_interests
ORDER BY common_interests DESC| Задача | SQL подход | Graph подход |
|---|---|---|
| Друзья друзей | 2 JOIN | 1 простой запрос |
| 6 рукопожатий | 6 JOIN (очень медленно) | Один запрос с глубиной 6 |
| Кратчайший путь | Рекурсивные CTE | Встроенный алгоритм |
Популярные решения:
| БД | Особенности | Когда использовать |
|---|---|---|
| Neo4j | Самая популярная, Cypher | Социальные сети, рекомендации |
| Amazon Neptune | Managed, AWS | AWS-проекты |
| ArangoDB | Multi-model (graph + document) | Гибридные сценарии |
| JanusGraph | Распределённая, open source | Big Data графы |
Реальные примеры:
- LinkedIn — граф профессиональных связей (800M+ узлов)
- Airbnb — граф доверия для предотвращения мошенничества
- eBay — рекомендации на основе графа покупок
| Сценарий | Тип NoSQL | Примеры БД | Почему |
|---|---|---|---|
| Кеш, сессии | Key-Value | Redis, Memcached | O(1) доступ, TTL |
| Очереди задач | Key-Value | Redis, RabbitMQ | Pub/Sub, списки |
| CMS, каталог товаров | Document | MongoDB | Гибкая схема |
| Логи, события | Document / Column | MongoDB, Cassandra | Append-only, масштабирование |
| Аналитика, отчёты | Column-family | ClickHouse, Cassandra | Агрегации по столбцам |
| Временные ряды (IoT) | Column-family | InfluxDB, TimescaleDB | Оптимизация для time-series |
| Социальные сети | Graph | Neo4j | Связи между пользователями |
| Рекомендации | Graph | Neo4j, Neptune | «Похожие товары» |
| Fraud detection | Graph | Neo4j | Поиск подозрительных паттернов |
| Критерий | SQL (PostgreSQL, MySQL) | NoSQL (MongoDB, Redis) |
|---|---|---|
| Модель данных | Таблицы, строки, столбцы | Документы, ключ-значение, графы |
| Схема | Строгая, заранее определённая | Гибкая, может меняться |
| Язык запросов | SQL (стандартизирован) | Разный для каждой БД |
| Транзакции | ACID (полная поддержка) | Часто BASE (eventual consistency) |
| Связи | JOIN, внешние ключи | Денормализация, вложенные документы |
| Масштабирование | Вертикальное (сложно горизонтально) | Горизонтальное (шардинг) |
| Консистентность | Строгая | Часто eventual |
| Зрелость | 40+ лет, проверено временем | 15+ лет, быстро развивается |
| Свойство | Описание |
|---|---|
| Atomicity | Транзакция выполняется полностью или не выполняется вообще |
| Consistency | БД всегда в согласованном состоянии |
| Isolation | Параллельные транзакции не влияют друг на друга |
| Durability | Завершённые транзакции сохраняются даже при сбое |
# ACID пример: перевод денег
with transaction.atomic():
sender.balance -= 100
sender.save()
receiver.balance += 100
receiver.save()
# Если здесь ошибка — откатится ВСЁ| Свойство | Описание |
|---|---|
| Basically Available | Система всегда отвечает (возможно, устаревшими данными) |
| Soft state | Состояние может меняться со временем без внешнего воздействия |
| Eventual consistency | Данные станут согласованными... когда-нибудь |
# BASE пример: счётчик лайков
redis.incr("post:123:likes") # Мгновенно
# Реплики получат обновление через несколько миллисекунд
# Пользователь может увидеть 999 лайков вместо 1000 — это ОКВ реальных проектах часто используют несколько баз данных, каждую для своей задачи:
┌─────────────────────────────────────────────────────────────┐
│ Веб-приложение │
└─────────────────────────────────────────────────────────────┘
│ │ │ │
▼ ▼ ▼ ▼
┌──────────┐ ┌─────────┐ ┌─────────┐ ┌─────────┐
│PostgreSQL│ │ Redis │ │ MongoDB │ │ Neo4j │
│ │ │ │ │ │ │ │
│ Заказы │ │ Кеш │ │ Логи │ │ Рекомен-│
│ Платежи │ │ Сессии │ │ События │ │ дации │
│ Юзеры │ │ Очереди │ │ │ │ │
└──────────┘ └─────────┘ └─────────┘ └─────────┘
Пример архитектуры интернет-магазина:
| Данные | БД | Причина |
|---|---|---|
| Пользователи, заказы, платежи | PostgreSQL | ACID, транзакции |
| Сессии, корзина | Redis | Скорость, TTL |
| Каталог товаров | MongoDB | Разные атрибуты у товаров |
| Поисковый индекс | Elasticsearch | Полнотекстовый поиск |
| Рекомендации | Neo4j | «С этим товаром покупают» |
| Аналитика | ClickHouse | Быстрые агрегации |
✅ Используй NoSQL, если:
| Критерий | Пример |
|---|---|
| Гибкая/меняющаяся схема | Каталог товаров с разными атрибутами |
| Горизонтальное масштабирование | Миллионы пользователей, петабайты данных |
| Высокая скорость записи | Логи, события, IoT-данные |
| Кеширование | Сессии, временные данные |
| Связи между сущностями | Социальные сети, рекомендации |
| Eventual consistency допустима | Счётчики лайков, просмотров |
❌ Оставайся на SQL, если:
| Критерий | Пример |
|---|---|
| Нужны ACID-транзакции | Финансовые операции, платежи |
| Сложные JOIN и отчёты | Бухгалтерия, ERP-системы |
| Строгая схема данных | Регулируемые отрасли (медицина, финансы) |
| Небольшой проект | Стартап на ранней стадии |
| Команда знает только SQL | Не усложняй без необходимости |
# ❌ Плохо: финансовые транзакции в MongoDB
def transfer_money(from_user, to_user, amount):
# Нет гарантии атомарности между документами!
db.users.update_one({"_id": from_user}, {"$inc": {"balance": -amount}})
# Что если здесь произойдёт сбой?
db.users.update_one({"_id": to_user}, {"$inc": {"balance": amount}})Решение: Используй PostgreSQL для финансов.
# ❌ Плохо: Redis как основное хранилище
redis.set("user:123", json.dumps(user_data))
# Что если Redis перезапустится? Данные потеряны!Решение: Redis — для кеша и временных данных. Основные данные — в PostgreSQL.
# ❌ Плохо: дублирование данных везде
{
"_id": "order_1",
"user": {"name": "Alice", "email": "alice@example.com"}, # Копия!
"items": [...]
}
# Если Alice сменит email — нужно обновить ВСЕ заказы!Решение: Денормализуй только то, что читается часто и меняется редко.
# ❌ Плохо: хаос в структуре документов
{"name": "Alice", "age": 25}
{"userName": "Bob", "years_old": "thirty"} # Разные поля, разные типы!Решение: Используй валидацию схемы (JSON Schema в MongoDB, Pydantic в Python).
1. Нужны ли ACID-транзакции?
├─ Да → PostgreSQL / MySQL
└─ Нет → продолжаем
2. Какой тип данных?
├─ Табличные, связанные → PostgreSQL
├─ Документы (JSON) → MongoDB
├─ Ключ-значение → Redis
├─ Временные ряды → InfluxDB / TimescaleDB
├─ Графы → Neo4j
└─ Логи, события → Elasticsearch / ClickHouse
3. Какой масштаб?
├─ < 1M записей → PostgreSQL справится
├─ 1M – 100M → PostgreSQL с оптимизацией или NoSQL
└─ > 100M → Скорее всего, нужен NoSQL или шардинг
4. Какая нагрузка?
├─ Больше чтения → Кеш (Redis) + любая БД
├─ Больше записи → Cassandra, MongoDB
└─ Аналитика → ClickHouse, BigQuery
💬 Комментарий преподавателя: Redis — универсальный инструмент. Он почти всегда есть в стеке. Даже если не используется на старте, его часто добавляют позже для кэширования, очередей и хранения сессий. Начните с PostgreSQL + Redis — это покрывает 90% задач.
Хотя Django предоставляет абстракции для кеша и сессий, иногда полезно работать с Redis напрямую через redis-py.
pip install redisБез запуска Redis работать не будет!
redis-serverimport redis
# Подключение
r = redis.Redis(host='localhost', port=6379, db=0, decode_responses=True)
# Строки (самый простой тип)
r.set("user:1:name", "Alice")
r.get("user:1:name") # "Alice"
r.set("user:1:name", "Alice", ex=3600) # с TTL 1 час
# Счётчики
r.incr("page:views") # атомарный инкремент
r.incrby("page:views", 10)
# Хеши (как словари)
r.hset("user:1", mapping={"name": "Alice", "email": "alice@example.com"})
r.hget("user:1", "name") # "Alice"
r.hgetall("user:1") # {"name": "Alice", "email": "..."}
# Списки (очереди)
r.lpush("queue:emails", "email1", "email2")
r.rpop("queue:emails") # "email1" (FIFO)
# Множества
r.sadd("article:1:tags", "python", "django", "redis")
r.smembers("article:1:tags") # {"python", "django", "redis"}
# Sorted Sets (для рейтингов, лидербордов)
r.zadd("leaderboard", {"alice": 100, "bob": 85, "charlie": 92})
r.zrevrange("leaderboard", 0, 2, withscores=True) # топ-3
# TTL и удаление
r.expire("user:1:name", 300) # установить TTL
r.ttl("user:1:name") # оставшееся время
r.delete("user:1:name")HTTP-протокол не сохраняет состояния. Чтобы «помнить» пользователя, его действия и не делать одни и те же вычисления много раз — используются куки, сессии и кеш.
- HTTP stateless — каждый запрос сам по себе, без истории.
- Cookie — способ сохранять небольшие данные на стороне клиента (браузера).
- Session — способ сохранять пользовательские данные на сервере, привязанные к уникальному
sessionid, передаваемому в Cookie. - Cache — быстрая память для хранения часто используемых данных (не обязательно связанных с пользователем).
Куки — это пары ключ:значение, которые браузер хранит локально и отправляет на сервер с каждым HTTP-запросом к
соответствующему домену.
Примеры применения:
- Сохранение корзины товаров
- Запоминание темы оформления
- Предзаполнение форм
- Авторизация через
sessionid

Куки существуют только на уровне HTTP запроса! Их может запоминать браузер, но прямого отношения к серверу они не имеют!
Пример установки/удаления cookie с флагами безопасности:
from django.http import HttpResponse
resp = HttpResponse("ok")
resp.set_cookie(
"theme", "dark", max_age=7*24*3600,
secure=True, httponly=True, samesite="Lax"
)
# ...
resp.delete_cookie("theme")| Флаг | Описание | Рекомендация |
|---|---|---|
secure=True |
Cookie передаётся только по HTTPS | ✅ Всегда в production |
httponly=True |
Cookie недоступна из JavaScript (защита от XSS) | ✅ Для sessionid, токенов |
samesite="Strict" |
Cookie отправляется только с того же сайта | Максимальная защита от CSRF |
samesite="Lax" |
Cookie отправляется при навигации, но не при POST с других сайтов | ✅ Рекомендуемый баланс |
samesite="None" |
Cookie отправляется всегда (требует secure=True) |
Только для cross-site сценариев |
max_age |
Время жизни в секундах | Зависит от сценария |
expires |
Дата истечения (альтернатива max_age) | Используйте max_age |
⚠️ Важно: Django по умолчанию устанавливаетSESSION_COOKIE_HTTPONLY = TrueиSESSION_COOKIE_SAMESITE = "Lax".
Обычные cookies можно подделать на клиенте. Signed cookies защищены криптографической подписью — Django проверяет, что значение не было изменено.
# Установка подписанной cookie
response.set_signed_cookie(
"user_preference",
"dark_mode",
salt="user-prefs", # дополнительная защита
max_age=3600
)
# Чтение подписанной cookie
try:
value = request.get_signed_cookie(
"user_preference",
salt="user-prefs",
max_age=3600 # проверка срока действия
)
except (KeyError, signing.BadSignature):
value = None # cookie отсутствует или подделанаКогда использовать:
- Хранение предпочтений пользователя
- Данные, которые не должны быть изменены клиентом
- Альтернатива сессиям для небольших данных
📌 Signed cookies используют
SECRET_KEY— при его смене все подписи станут невалидными.
Документация: https://docs.djangoproject.com/en/stable/topics/http/sessions/ — основы сессий; настройки: https://docs.djangoproject.com/en/stable/ref/settings/#sessions
Сессия — это механизм сохранения информации между запросами одного и того же пользователя. Чаще всего для реализации сессий используется привязка к куки.
Как это работает в Django:
Браузер → POST /login → Сервер:
- создаёт Session в БД
- возвращает Set-Cookie: sessionid=<uuid>
Браузер → GET /profile → Cookie: sessionid → Сервер:
- достаёт данные из request.session
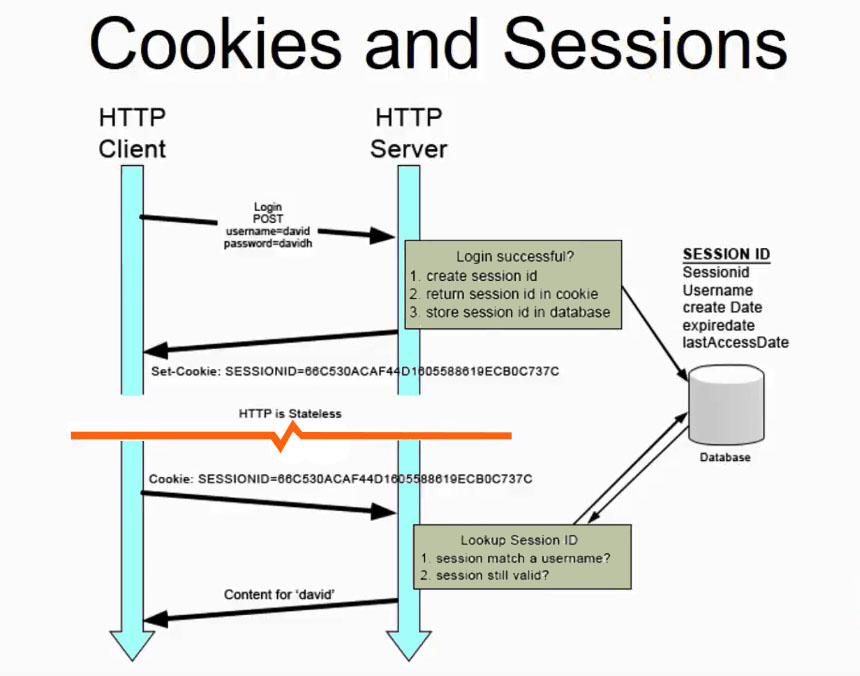
Где хранятся данные:
Django поддерживает несколько backends для хранения сессий через настройку SESSION_ENGINE:
| Backend | SESSION_ENGINE | Плюсы | Минусы |
|---|---|---|---|
| Database (по умолчанию) | django.contrib.sessions.backends.db |
Надёжно, просто | Нагрузка на БД |
| Cache | django.contrib.sessions.backends.cache |
Быстро | Данные теряются при перезапуске |
| Cached DB | django.contrib.sessions.backends.cached_db |
Быстро + надёжно | Сложнее настройка |
| File | django.contrib.sessions.backends.file |
Просто | Медленно, проблемы с масштабированием |
| Signed Cookie | django.contrib.sessions.backends.signed_cookies |
Без хранилища | Ограничение 4KB, данные видны клиенту |
# settings.py
# 1. Настраиваем кеш (Redis)
CACHES = {
"default": {
"BACKEND": "django_redis.cache.RedisCache",
"LOCATION": "redis://127.0.0.1:6379/1",
"OPTIONS": {"CLIENT_CLASS": "django_redis.client.DefaultClient"},
}
}
# 2. Используем кеш для сессий
SESSION_ENGINE = "django.contrib.sessions.backends.cache"
SESSION_CACHE_ALIAS = "default"
# Или cached_db для надёжности (кеш + БД как fallback)
# SESSION_ENGINE = "django.contrib.sessions.backends.cached_db"💡 Рекомендация: Для production используйте
cached_db— это даёт скорость Redis и надёжность БД.
Предпосылки настройки (обычно включены в типичном проекте):
'django.contrib.sessions'вINSTALLED_APPS'django.contrib.sessions.middleware.SessionMiddleware'вMIDDLEWARE- (Рекомендуется)
'django.contrib.auth.middleware.AuthenticationMiddleware'
# Работа с сессией в Django
request.session['visited'] = True
# Проверка
if request.session.get('visited'):
...
# Удаление одного ключа
del request.session['visited']
# Полная очистка сессии (удаляет все данные и создаёт новый sessionid)
request.session.flush()
# Очистка данных без смены sessionid
request.session.clear()💡
flush()рекомендуется при logout — это предотвращает session fixation атаки.
def post_comment(request, comment):
if request.session.get('has_commented', False):
return HttpResponse("You've already commented.")
request.session['has_commented'] = True
return HttpResponse("Thanks!")# ❌ Неправильно — datetime не сериализуется в JSON
# request.session['last_action'] = timezone.now()
# ✅ Правильно — сохраняем как ISO-строку
from django.utils import timezone
request.session['last_action'] = timezone.now().isoformat()
# При чтении преобразуем обратно
from datetime import datetime
last_action_str = request.session.get('last_action')
if last_action_str:
last_action = datetime.fromisoformat(last_action_str)
⚠️ Сессии сериализуются в JSON, поэтому можно хранить только:str,int,float,bool,list,dict,None.
# Установить время жизни текущей сессии (секунды)
request.session.set_expiry(3600) # 1 часfrom django.contrib.sessions.backends.db import SessionStore
s = SessionStore()
s['foo'] = 'bar'
s.create()
s.session_key # сохранённый ключ- Данные сессии сериализуются (по умолчанию JSON), поэтому объекты должны быть сериализуемыми. Подробно разберём сериализацию далее по курсу.
- Данные сохраняются только при изменении
request.sessionкак объекта
request.session['foo'] = 'bar' # сохранится
request.session['foo']['x'] = 1 # ❌ не сохранитсяПри вложенной мутации пометьте сессию изменённой:
request.session.setdefault("cart", {})["id123"] = 2
request.session.modified = True # зафиксировать изменения для сохранения✅ Можно настроить:
SESSION_SAVE_EVERY_REQUEST = Truepython manage.py clearsessionsКоманду рекомендуется запускать периодически (cron / periodic job) — подробнее о планировании задач разберём позже по курсу.
Или вручную:
from django.contrib.sessions.models import Session
Session.objects.filter(...).delete()Документация: https://docs.djangoproject.com/en/stable/topics/cache/ — основы кеширования; настройки: https://docs.djangoproject.com/en/stable/ref/settings/#std:setting-CACHES; per-view cache: https://docs.djangoproject.com/en/stable/topics/cache/#the-per-view-cache
Кеш (cache) — это промежуточное хранилище данных, которое позволяет быстро получить результат без повторного выполнения дорогостоящей операции.
Представьте: вы каждый раз открываете холодильник, чтобы посмотреть, есть ли молоко. Это занимает время. Но если вы запомните, что молоко есть, — вам не нужно открывать холодильник снова. Это и есть кеширование.
В контексте веб-приложений кеш помогает избежать:
- Повторных запросов к базе данных
- Повторных вычислений (агрегации, сортировки)
- Повторных запросов к внешним API
- Повторного рендеринга шаблонов

| Операция | Примерное время |
|---|---|
| Чтение из RAM (Redis) | ~0.1 мс |
| Чтение из SSD | ~0.1-1 мс |
| Запрос к PostgreSQL (простой) | ~1-10 мс |
| Запрос к PostgreSQL (сложный JOIN) | ~50-500 мс |
| Запрос к внешнему API | ~100-1000 мс |
Разница может быть в 100–1000 раз! Если главная страница делает 10 запросов к БД по 50 мс каждый — это 500 мс. С кешем — 1 мс.
Хорошие кандидаты для кеширования:
- Данные, которые читаются часто, но меняются редко (список категорий, настройки)
- Результаты тяжёлых вычислений (статистика, отчёты)
- Ответы внешних API (курсы валют, погода)
- Отрендеренные фрагменты HTML (сайдбар, меню)
- Сериализованные данные для API
Плохие кандидаты:
- Данные, которые меняются при каждом запросе
- Персонализированные данные (если много пользователей)
- Данные, где критична актуальность (баланс счёта)
- Hit Rate — процент запросов, которые нашли данные в кеше. Цель: >90%
- Miss Rate — процент промахов (данных нет в кеше)
- TTL (Time To Live) — время жизни записи в кеше
- Eviction — вытеснение старых данных при нехватке памяти
Hit Rate = Cache Hits / (Cache Hits + Cache Misses) × 100%
💡 Если Hit Rate низкий — возможно, TTL слишком короткий или ключи генерируются неправильно.
Существует несколько паттернов работы с кешем. Выбор зависит от требований к консистентности данных и нагрузки.
Самая популярная стратегия. Приложение само управляет кешем.
Чтение:
1. Проверяем кеш
2. Если есть (cache hit) → возвращаем
3. Если нет (cache miss) → читаем из БД → сохраняем в кеш → возвращаем
Запись:
1. Пишем в БД
2. Инвалидируем (удаляем) кеш
def get_article(article_id):
key = f"article:{article_id}"
article = cache.get(key)
if article is None: # cache miss
article = Article.objects.get(pk=article_id)
cache.set(key, article, timeout=3600)
return article
def update_article(article_id, data):
article = Article.objects.get(pk=article_id)
article.title = data['title']
article.save()
# Инвалидируем кеш
cache.delete(f"article:{article_id}")✅ Плюсы: Простота, кешируются только нужные данные ❌ Минусы: Первый запрос всегда медленный (cold start)
Запись идёт через кеш. Данные всегда синхронизированы.
Запись:
1. Пишем в кеш
2. Кеш синхронно пишет в БД
Чтение:
1. Всегда читаем из кеша
def save_article(article):
article.save() # БД
cache.set(f"article:{article.id}", article, timeout=3600) # Кеш✅ Плюсы: Данные всегда актуальны, нет cache miss после записи ❌ Минусы: Запись медленнее (2 операции), кешируются даже редко читаемые данные
Асинхронная запись в БД. Сначала пишем в кеш, потом фоново в БД.
Запись:
1. Пишем в кеш
2. Асинхронно (через очередь) пишем в БД
Чтение:
1. Читаем из кеша
def increment_views(article_id):
# Быстро инкрементируем в Redis
cache.incr(f"article:{article_id}:views")
# Периодически синхронизируем с БД (через Celery task)
sync_views_to_db.delay(article_id)✅ Плюсы: Очень быстрая запись ❌ Минусы: Риск потери данных при сбое, сложность реализации
Кеш сам загружает данные. Приложение работает только с кешем.
Чтение:
1. Запрашиваем у кеша
2. Кеш сам загружает из БД при miss
В Django это можно реализовать через get_or_set:
def get_article(article_id):
return cache.get_or_set(
f"article:{article_id}",
lambda: Article.objects.get(pk=article_id),
timeout=3600
)| Сценарий | Рекомендуемая стратегия |
|---|---|
| Чтение >> Запись (блог, каталог) | Cache-Aside |
| Критичная консистентность | Write-Through |
| Высокая нагрузка на запись (счётчики, логи) | Write-Behind |
| Простота кода важнее всего | Read-Through (get_or_set) |
Проблема: Кеш истёк, 1000 запросов одновременно идут в БД.
Решение: Блокировка или вероятностное обновление:
import random
def get_with_early_refresh(key, fetch_func, timeout=3600):
data, expires_at = cache.get(key, (None, 0))
# Вероятностное раннее обновление
if data and time.time() < expires_at:
# 5% шанс обновить заранее
if random.random() < 0.05 and time.time() > expires_at - 60:
data = fetch_func()
cache.set(key, (data, time.time() + timeout), timeout)
return data
# Cache miss — обновляем
data = fetch_func()
cache.set(key, (data, time.time() + timeout), timeout)
return dataПроблема: Данные изменились, но в кеше старая версия.
Решения:
- Короткий TTL
- Инвалидация через сигналы
- Версионирование ключей
# Вместо:
Article.objects.filter(published=True).order_by('-date')[:5]
# Лучше:
articles = cache.get('homepage_articles')
if not articles:
articles = Article.objects.filter(...).all()
cache.set('homepage_articles', articles, timeout=3600)Альтернатива короче:
articles = cache.get_or_set(
"homepage:articles:v1",
lambda: Article.objects.filter(published=True).order_by("-date")[:5],
timeout=3600,
)Счётчики (зависят от backend, поддерживаются Redis/Memcached):
cache.incr("counter:visits", ignore_key_check=True)
# cache.decr("counter:visits")| Хранилище | Плюсы | Минусы |
|---|---|---|
| Redis | Быстро, работает в памяти, масштабируется | Требует установки и сервера |
| Memcached | Очень быстрый, простой | Только строковые ключи |
| FileBased | Не требует серверов | Медленный на больших объёмах |
| Database | Ничего не нужно настраивать | Нагрузка на БД |
| DummyCache | Ничего не делает (для dev) | Нет кеша :) |
Установка backend:
python -m pip install django-redisCACHES = {
"default": {
"BACKEND": "django_redis.cache.RedisCache",
"LOCATION": "redis://127.0.0.1:6379/1",
"OPTIONS": {"CLIENT_CLASS": "django_redis.client.DefaultClient"},
"TIMEOUT": 3600,
"KEY_PREFIX": "myapp",
}
}from django.core.cache import cache
cache.set("key", "value", timeout=60)
cache.get("key") # "value"
cache.delete("key")Массовые операции:
cache.set_many({"a": 1, "b": 2})
cache.get_many(["a", "b"])
cache.delete_many(["a", "b"])Версии позволяют инвалидировать кеш без удаления ключей — полезно при деплое:
# Установка с версией
cache.set("articles", data, version=1)
# Чтение конкретной версии
cache.get("articles", version=1)
# Инкремент версии (инвалидирует старый кеш)
cache.incr_version("articles")
# Глобальная версия в settings.py
CACHES = {
"default": {
# ...
"VERSION": 1, # увеличьте при деплое для сброса всего кеша
}
}"There are only two hard things in Computer Science: cache invalidation and naming things." — Phil Karlton
Инвалидация кеша — это процесс удаления или обновления устаревших данных в кеше. Звучит просто, но на практике это одна из самых коварных проблем в программировании.
-
Связанные данные. Изменение одной сущности может влиять на множество кешей:
- Изменили статью → нужно обновить: кеш статьи, кеш списка статей, кеш категории, кеш тегов, кеш RSS, кеш sitemap...
-
Распределённые системы. Кеш может быть на нескольких серверах, и они должны синхронизироваться.
-
Race conditions. Между чтением из БД и записью в кеш данные могут измениться.
-
Каскадные зависимости. Изменение автора → все его статьи → все комментарии к статьям...
Самый простой подход — данные автоматически устаревают через заданное время.
cache.set("articles:list", articles, timeout=300) # 5 минут✅ Плюсы: Простота, гарантированное обновление ❌ Минусы: Данные могут быть устаревшими до истечения TTL
Когда использовать:
- Данные, где небольшая задержка допустима (новости, каталог)
- Внешние API (курсы валют — обновляются раз в час)
Явная инвалидация при изменении данных.
# blog/signals.py
from django.core.cache import cache
from django.db.models.signals import post_save, post_delete
from django.dispatch import receiver
from .models import Article
@receiver([post_save, post_delete], sender=Article)
def invalidate_article_cache(sender, instance, **kwargs):
"""Сбрасываем кеш при изменении статьи."""
# 1. Кеш конкретной статьи
cache.delete(f"article:{instance.pk}")
# 2. Кеш списка статей (может быть несколько)
cache.delete("homepage:articles")
cache.delete(f"category:{instance.category_id}:articles")
# 3. Кеш автора
cache.delete(f"author:{instance.author_id}:articles")✅ Плюсы: Мгновенное обновление ❌ Минусы: Нужно знать все связанные ключи, легко что-то забыть
📌 Подробнее о сигналах — в лекции 26.
Вместо удаления — меняем версию, старые ключи просто игнорируются.
# Глобальная версия для всех статей
ARTICLES_VERSION = cache.get("articles:version", 1)
def get_articles():
key = f"articles:list:v{ARTICLES_VERSION}"
return cache.get_or_set(key, fetch_articles, timeout=3600)
def invalidate_articles():
# Инкрементируем версию — все старые ключи становятся "мусором"
cache.incr("articles:version")✅ Плюсы: Атомарность, нет race conditions ❌ Минусы: Старые данные занимают память до eviction
Группировка ключей по тегам — можно инвалидировать всё, связанное с тегом.
# Псевдокод (требует специальной реализации или библиотеки)
cache.set("article:1", data, tags=["articles", "category:5", "author:3"])
cache.set("article:2", data, tags=["articles", "category:5", "author:7"])
# Инвалидируем всё в категории 5
cache.invalidate_tag("category:5") # удалит article:1 и article:2💡 Django из коробки не поддерживает теги. Используйте
django-cacheopsили реализуйте через Redis Sets.
Обновляем кеш сразу при записи в БД.
def update_article(article_id, data):
article = Article.objects.get(pk=article_id)
for key, value in data.items():
setattr(article, key, value)
article.save()
# Сразу обновляем кеш (не удаляем!)
cache.set(f"article:{article_id}", article, timeout=3600)
# Но списки всё равно инвалидируем
cache.delete("homepage:articles")✅ Плюсы: Нет cache miss после обновления ❌ Минусы: Сложнее поддерживать консистентность списков
# ❌ Плохо — забыли про список
@receiver(post_save, sender=Article)
def invalidate(sender, instance, **kwargs):
cache.delete(f"article:{instance.pk}")
# А homepage:articles остался со старыми данными!# ❌ Плохо — между get и set данные могут измениться
article = Article.objects.get(pk=1) # версия 1
# ... кто-то обновил статью до версии 2 ...
cache.set("article:1", article) # записали устаревшую версию 1!Решение: Используйте get_or_set или версионирование.
# ❌ Плохо — кеш удалится, даже если транзакция откатится
with transaction.atomic():
article.save()
cache.delete(f"article:{article.pk}") # Опасно!
raise Exception("Rollback") # Кеш уже удалён, но данные не сохраненыРешение: Инвалидируйте после коммита:
from django.db import transaction
def save_article(article):
article.save()
transaction.on_commit(
lambda: cache.delete(f"article:{article.pk}")
)| Сценарий | Рекомендуемый подход |
|---|---|
| Простой проект, допустима задержка | TTL (5-15 минут) |
| Критична актуальность | Event-based + сигналы |
| Много связанных сущностей | Версионирование или теги |
| Высокая нагрузка на запись | Write-through |
| Микросервисы | Event-driven (через очереди) |
Вместо разбросанных cache.delete() — один модуль:
# cache_utils.py
from django.core.cache import cache
from django.db import transaction
class CacheInvalidator:
"""Централизованная инвалидация кеша."""
@staticmethod
def invalidate_article(article_id: int, category_id: int = None):
"""Инвалидирует все кеши, связанные со статьёй."""
keys = [
f"article:{article_id}",
"homepage:articles",
"sitemap:articles",
]
if category_id:
keys.append(f"category:{category_id}:articles")
cache.delete_many(keys)
@staticmethod
def invalidate_article_on_commit(article):
"""Безопасная инвалидация после коммита транзакции."""
transaction.on_commit(
lambda: CacheInvalidator.invalidate_article(
article.pk,
article.category_id
)
)from django.views.decorators.cache import cache_page
@cache_page(60 * 15)
def my_view(request):
...Или в urls.py:
path("foo/", cache_page(900)(views.foo_view)){% load cache %}
{% cache 300 sidebar %}
...HTML sidebar...
{% endcache %}MIDDLEWARE = [
"django.middleware.cache.UpdateCacheMiddleware",
# ...
"django.middleware.cache.FetchFromCacheMiddleware",
]
CACHE_MIDDLEWARE_SECONDS = 300cache.clear()from django.views.decorators.cache import never_cache
@never_cache
def dynamic_view(request):
...- NoSQL — альтернатива реляционным БД для специфических сценариев (кеш, документы, графы).
- CAP-теорема — в распределённой системе можно выбрать только 2 из 3: Consistency, Availability, Partition Tolerance.
- Redis — универсальный инструмент для кеша, сессий, очередей, rate limiting.
- Куки — данные на клиенте (браузере), используйте флаги безопасности.
- Сессии — данные на сервере, привязанные к пользователю через sessionid.
- Кеш — быстрая память для ускорения работы, не связана напрямую с пользователем.
- Инвалидация кеша — критически важна, используйте сигналы или версионирование.
- Чем отличаются куки от сессий?
- Почему сессии нельзя использовать для анонимных пользователей везде?
- Где по умолчанию Django хранит сессии?
- Что произойдёт, если модифицировать
request.session['key']['value']? - Как бы вы реализовали кеширование главной страницы?
- Как очистить все сессии, старше 30 дней?
- Какой SESSION_ENGINE лучше использовать в production и почему?
- Зачем нужны Signed Cookies?
-
Работа с сессиями:
- Создайте view, которая считает количество посещений пользователя
- Реализуйте "корзину" товаров через сессии
-
Кеширование:
- Закешируйте список статей на главной странице
- Добавьте инвалидацию кеша при создании новой статьи
Реализуйте счётчик просмотров для статей блога:
- Используйте сессии, чтобы один пользователь не накручивал просмотры
- Храните счётчик в Redis для быстродействия
- Периодически синхронизируйте с БД
Реализуйте функционал «Недавно просмотренные статьи»:
- Храните список последних 5 просмотренных статей в сессии
- Отображайте их в сайдбаре
Реализуйте ограничение на количество комментариев:
- Не более 5 комментариев в минуту от одного пользователя
- Используйте Redis для хранения счётчиков
- Показывайте пользователю, сколько секунд осталось до сброса лимита
Для блога реализуйте:
- Кеширование списка статей на 10 минут
- Кеширование отдельной статьи на 1 час
- Автоматическую инвалидацию при редактировании статьи
- Используйте сигналы
post_saveиpost_delete
- Переключите хранение сессий на Redis (
cached_db) - Сравните производительность с database backend
- Напишите management-команду для миграции существующих сессий
← Лекция 24: ClassBaseView | Лекция 26: Логирование. Middleware. Signals. Messages. Manage commands →